4.2.1 Steptypen
In der Stepübersicht werden für eine ausgewählte Pipeline alle Steps sowie deren Bearbeitungsoptionen angezeigt.
Ein Step stellt eine Aufgabe dar. In einer Pipeline können Steps verschiedener Typen gemischt werden. Da Häckchen am Step setzt diesen auf aktiv oder inaktiv - inaktive Steps werden im Ausführungslauf übersprungen.
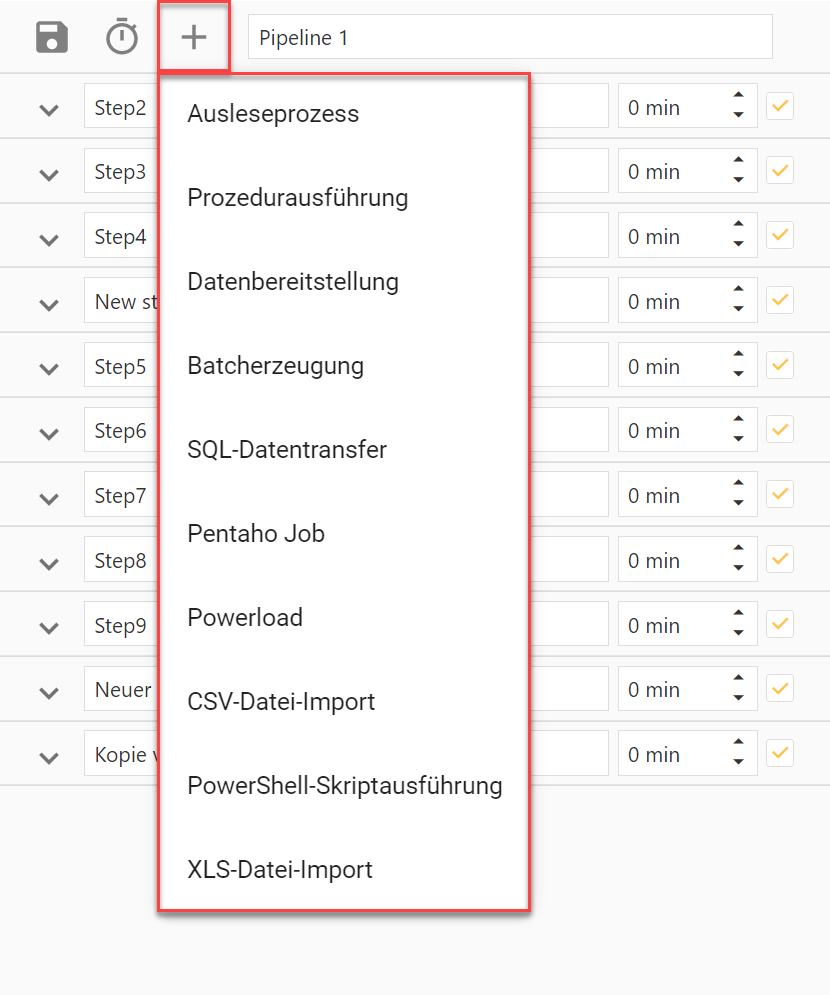
1. Ausleseprozess
Der Ausleseprozess liest Daten für ein Modul aus einer Datenquelle und schreibt sie in das Integrationsschema in OCT.
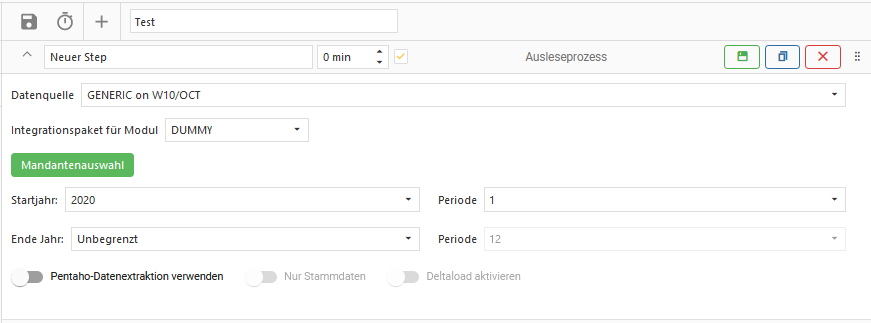
Datenquelle
Auswahl einer der angelegten Datenquellen.
Integrationspaket für Modul
Auswahl eines der aktivierten Module.
Die verfügbare Auswahl hängt von der ausgewählten Datenquelle ab.
Mandantenauswahl
Der grüne Button “Mandantenauswahl” öffnet den Dialog der “Mandantenauswahl”:
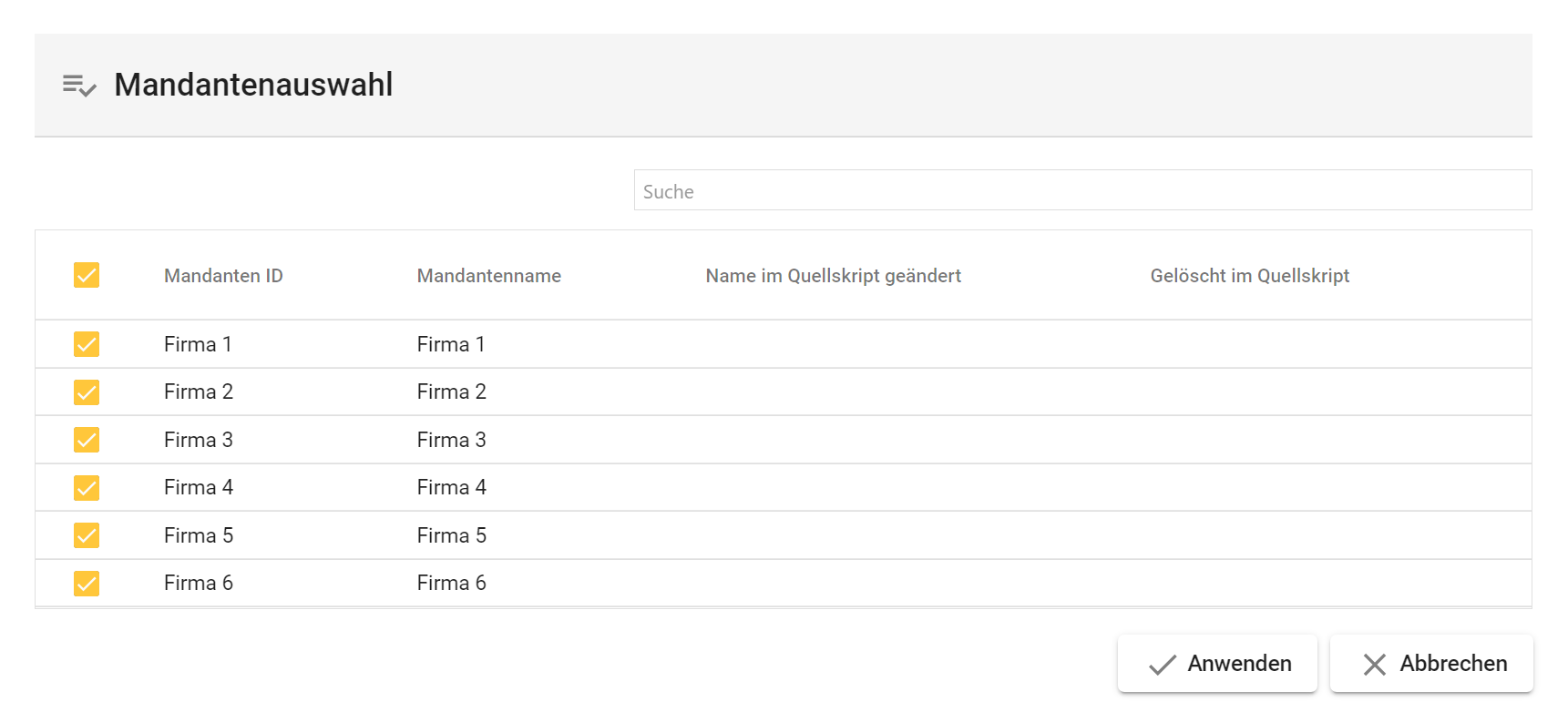
Suche
Durchsucht die Tabelle nach dem eingegebenen Inhalt.
Über ein kleines schwarzes Kreuz, am rechten Ende des Eingabefeldes, kann die Eingabe wieder gelöscht werden.
Aktivierung eines Mandanten
Ein Linksklick auf die Checkbox einer Zeile aktiviert den jeweiligen Mandanten.
Bei erfolgreicher Auswahl zeigt die jeweilige Checkbox einen Haken auf der eingestellten https://saxess-software.atlassian.net/wiki/spaces/OH/pages/445646542/6.+Datenbankeinstellungen#Hauptfarbe fest.
Die Checkbox auf Höhe der Spaltenköpfe (de-)aktiviert alle Mandanten.
Mandanten-ID
Zeigt die definierten Mandanten-ID des Mandanten.
Mandanten-Name
Zeigt den definierten Mandantennamen des Mandanten.
Im Dialog “Mandantenauswahl” aktivierte Mandanten, werden in dem Feld - rechts neben dem Button “Mandantenauswahl” - in der Form “Mandanten-ID - Mandantenname,….” angezeigt.
Startjahr und Periode
Auswahl des Startjahrs und der Startperiode ab der die Daten extrahiert werden sollen.
Es wird im Grundzustand das Startjahr = “2021” und die Periode = “1” ausgewählt.
Ende Jahr und Periode
Auswahl des Jahres und der Periode bis zu der die Daten extrahiert werden sollen.
Es wird im Grundzustand das Ende Jahr = “Unbegrenzt” und die Periode = “12” ausgewählt.
Mit der Auswahl “Unbegrenzt” werden ab dem gewählten Startjahr alle zukünftigen Jahre ausgelesen.
Pentaho-Datenextraktion verwenden
Schieberegler um zwischen reinem SQL Transfer und Pentaho Extraktion umzuschalten
SQL Transfer nur bei Vorsystemtyp MSSQL möglich.
Nur Stammdaten
Schieberegler um nur Stammdaten auszulesen.
Das Beschränken des Auslesens auf Stammdaten ist nur bei Pentaho-Paketen möglich.
Deltaload aktivieren
Schieberegler um den Deltaload zu aktivieren.
Das Aktivieren ist nur bei Pentaho-Paketen möglich.
Generisches Löschen verwenden
Die Aktivierung ruft die Prozedur agent.pDeleteIntegrationValues bzw. innerhalb der Prozedur die agent.pDeleteIntegrationValuesFIN auf.
Diese löscht im Integrations-Schema alle Stammdaten der ausgewählten Mandanten und von den Bewegungsdaten die ausgewählten Perioden der Mandanten.
Falls es für das ausgewählte Modul keine explizite pDeleteIntegrationValues....-Prozedur gibt wird die pDeleteIntegrationValuesGeneric Prozedur aufgerufen.
Diese versucht alle Integration-Tabellen des Moduls zu finden und darin Daten zu löschen.
Diese Option erfordert fortgeschrittenes Expertenwissen und sollte grundsätzlich erstmal aktiviert sein.
Post Bulkload ausführen
In diesem Schritt werden unter anderem auch die Stammdaten (Konten, Kostenobjekte) aus dem Integration-Schema in das Global-Schema synchronisiert.
Die Stammdaten im Global-Schema sind die führenden Stammdaten, welche auch bei der Bereitstellung der Daten im Result-Schema verwendet werden.
Neben den Stammdaten aus der Integration kann somit der Benutzer auch eigene Stammdaten einpflegen oder die Stammdaten aus dem Vorsystem editieren bzw. ergänzen.
2. Prozedurausführung
Der Step führt eine gepeicherte Prozedur in der aktiven OCT Datenbank aus.
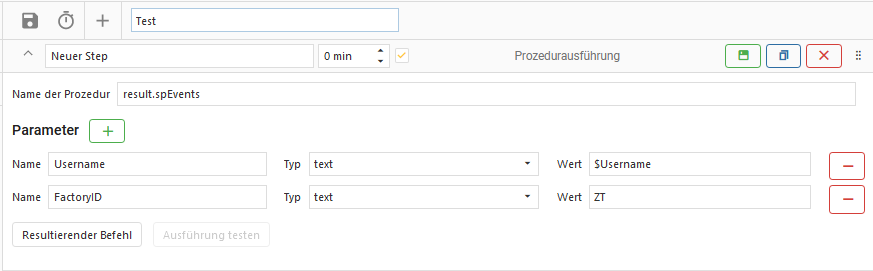
Name der Prozedur
Definiert den Namen der Prozedur, die ausgeführt werden soll.
Die Prozedur…
…ist in einer aktuellen OCT Datenbank gespeichert - Prozeduren in anderen Datenbanken können nicht aufgerufen werden.
…muss einen Returncode nach OCT Definition zurückgeben (200, 404...).
benötigt einen berechtigten ServiceUser von OCT für dessen Ausführung.
Parameter hinzufügen
Einer Prozedur können beliebig viele Parameter übergeben werden.
Es können globale Parameter referenziert werden mit $[Variablenname].
Ein grüner Button mit einem grünen “+” fügt einen neuen Parameter hinzu.
Name
Weißt dem Parameter einen Namen zu.
Parameter werden ohne “@” übergeben.
Typ
Definiert den Datentyp des Parameters.
Parameter können vom Typ “text” oder vom Typ “numeric” sein.
Wert
Übergibt den Parameter mit einem dazugehörigem Wert.
Mögliche Werte hängen von der Art des ausgewählten Typs ab.
Resultierender Befehl
Zeigt den resultierenden SQL-Befehl, welcher bei den aktuell ausgewählten Parametern & ihren Eigenschaften entstehen würde.
Ausführung testen
Testet den aktuell resultierenden SQL-Befehl auf dessen Funktionalität aus.
Ist der Befehl ungültig, so öffnet sich ein Fehler-Dialog.
3. Datenbereitstellung
Die Datenbereitstellung überführt die im Ausleseprozess ausgelesenen Daten aus dem Integration-Schema und stellt diese im Global- & im Result-Schema bereit. Logisch gesehen werden dadurch die extrahierten Daten an den Endanwender ausgeliefert.
Daten, die noch nicht durch den https://saxess-software.atlassian.net/wiki/spaces/OH/pages/445645281/4.2.1+Steptypen#1.-Ausleseprozess geladen wurden, können auch nicht bereitgestellt werden.
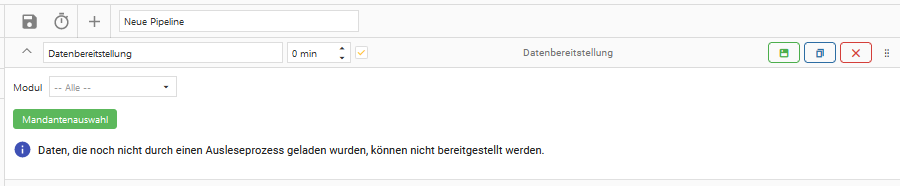
Datenquelle
Auswahl einer der angelegten Datenquellen.
Modul
Auswahl eines des aktivierten Moduls.
Die verfügbare Auswahl hängt von der ausgewählten Datenquelle ab.
Mandantenauswahl
Der grüne Button “Mandantenauswahl” öffnet den Dialog der “Mandantenauswahl”:
Suche
Durchsucht die Tabelle nach dem eingegebenen Inhalt.
Über ein kleines schwarzes Kreuz, am rechten Ende des Eingabefeldes, kann die Eingabe wieder gelöscht werden.
Aktivierung eines Mandanten
Ein Linksklick auf die Checkbox einer Zeile aktiviert den jeweiligen Mandanten.
Bei erfolgreicher Auswahl zeigt die jeweilige Checkbox einen Haken auf der eingestellten https://saxess-software.atlassian.net/wiki/spaces/OH/pages/445646542/6.+Datenbankeinstellungen#Hauptfarbe fest.
Die Checkbox auf Höhe der Spaltenköpfe (de-)aktiviert alle Mandanten.
Mandanten-ID
Zeigt die definierten Mandanten-ID des Mandanten.
Mandanten-Name
Zeigt den definierten Mandantennamen des Mandanten.
Im Dialog “Mandantenauswahl” aktivierte Mandanten, werden in dem Feld - rechts neben dem Button “Mandantenauswahl” - in der Form “Mandanten-ID - Mandantenname,….” angezeigt.
4. SQL-Datentransfer
Der Step SQL-Datentransfer liest Daten aus einer Datenquelle per SQL-Abfrage und speichert diese in einer Tabelle der OCT Datenbank.
Datenquelle
Auswahl einer der angelegten Datenquellen.
PreSQL
SQL-Statement. welches vor dem Datentransfer in der OCT-Datenbank ausgeführt werden soll.
Ein PreSQL-Statement ist optional.
Zieltabelle
Zieltabelle in der OCT-Datenbank, in welche die Daten übertragen werden.
SQL
SQL-Statement um die Daten aus der Datenquelle abzurufen.
Das SQL-Statement muss genau ein Recordset zurückgeben, welches exakt den Spalten der Zieltabelle entspricht.
PostSQL
SQL-Statement. welches nach dem Datentransfer in der OCT-Datenbank ausgeführt werden soll.
Ein PostSQL-Satement ist optional.
SQL-Abfrage-Test
Überprüft die Kombination aller verpflichtenden & optionalen SQL-Statements auf ihre Funktionalität.
Der Test öffnet dem Dialog “SQL-Abfrage-Test”. In diesem werden im Grundzustand die ersten 100Zeilen des z.B. SELECT-Statements angezeigt.
5. Pentaho Job
Über den Step “Pentaho Job” ist es möglich, einen beliebigen Pentaho-Job auszuführen ohne Bezug auf das Repository und dessen Konnektoren.
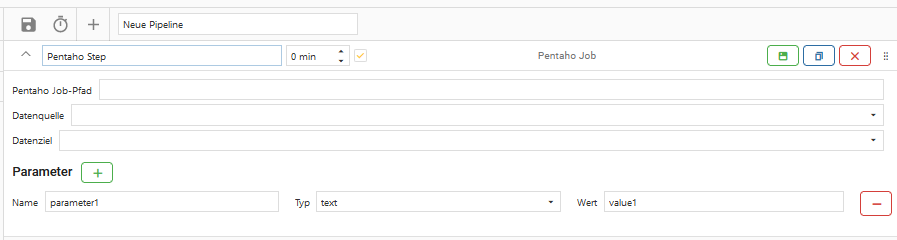
Pentaho Job-Pfad
Der Pfad zu einem Pentaho Job auf dem lokalen Dateisystem.
Datenquelle
Auswahl einer der angelegten Datenquellen.
Diese dient als Startpunkt des Prozesses.
Datenziel
Auswahl einer der angelegten Datenquellen.
Diese dient als Endpunkt des Prozesses.
Bei Datenquelle und Datenziel kann entweder kann eine bestehende Verbindung aus der Datenquellenverwaltung oder die eigene OCT-Datenbank ausgewählt werden.
Parameter hinzufügen
Einer Prozedur können beliebig viele Parameter übergeben werden.
Es können globale Parameter referenziert werden mit $[Variablenname].
Ein grüner Button mit einem grünen “+” fügt einen neuen Parameter hinzu.
Name
Weißt dem Parameter einen Namen zu.
Parameter werden ohne “@” übergeben.
Typ
Definiert den Datentyp des Parameters.
Parameter können vom Typ “text” oder vom Typ “numeric” sein.
Wert
Übergibt den Parameter mit einem dazugehörigem Wert.
Mögliche Werte hängen von der Art des ausgewählten Typs ab.
6. Powerload
Der Powerload öffnet und speichert jedes Produkt in der ausgewählten Struktur (Fabrik, Produktlinie). Er wird genutzt um formelbasierte Werte in Products neu zu berechnen, nachdem Werte importiert wurden.
Powerloading-Ziel
Das Feld öffnet mit einem Linksklick einen Dropdown, welcher die Struktur der 5.1. Navigationsleiste der Datenerfassung bis runter zu Produktlinie enthält:
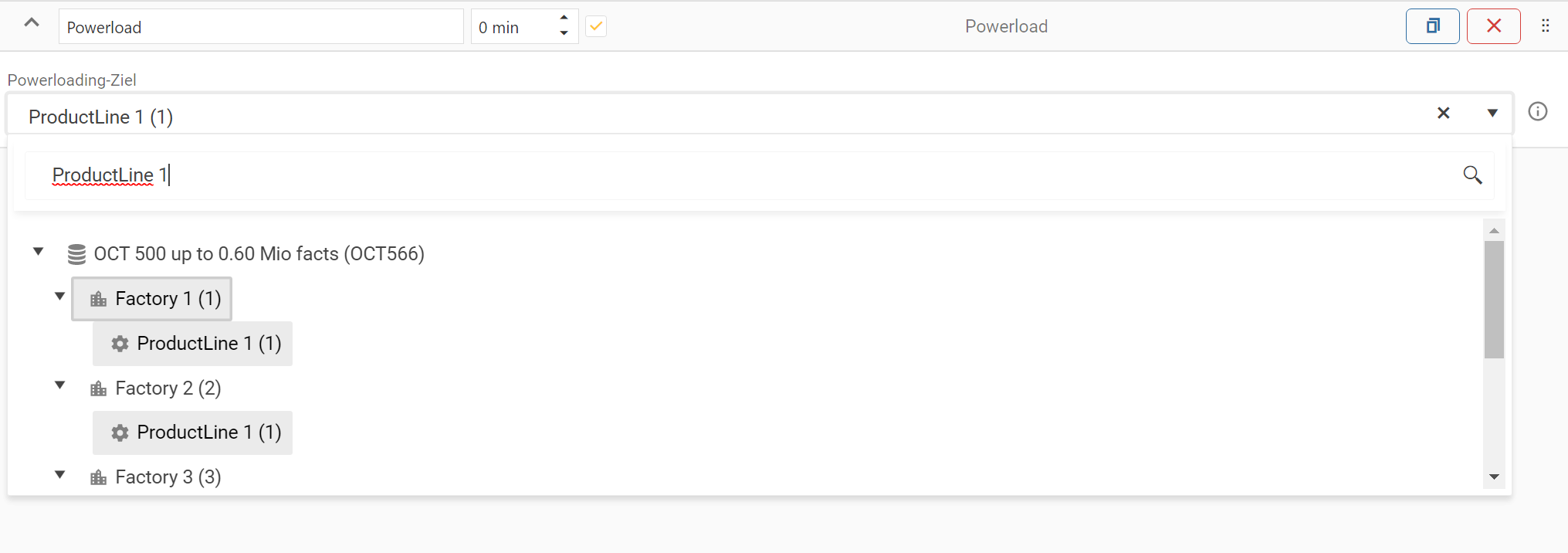
Ziel-Dropdown
Zeigt den Knoten an, für welchen der Powerload ausgeführt werden soll - dieses Feld ist im Grundzustand leer.
Ein Linksklick auf dieses Feld öffnet einen Dropdown mit einer Baumstruktur. Das Feld ist durch einen schwarzen Pfeil am rechten Rand gekennzeichnet.
Eine getätigte Auswahl kann durch ein “x” am rechten Feldrand gelöscht werden.
Such-Eingabefeld
Oberhalb der Baumstruktur ist ein Eingabefeld - gekennzeichnet durch die Lupe am rechten Rand.
In diesem Feld können (Teil-)Begriffe, zur Suche in der Baumstruktur, eingegeben werden.
Ein-/Ausklappen der Baumstruktur
Die oberste angezeigte Ebene ist die Cluster-Ebene.
Für diese Ebene kann man, durch kleine schwarze Pfeile links des Ebenennamens, die Struktur der dazugehörigen Unterebenen ein-/ausgeklappen.
Ein Linksklick auf den Namen der Ebene wählt diesen Knoten aus.
ACHTUNG: Nicht alle Formeln werden auch vom Powerloading unterstützt, dabei funktionieren nur…
…die folgenden Formeln im Grundzustand: https://docs.telerik.com/devtools/document-processing/libraries/radspreadprocessing/features/formulas/functions
…die von uns zusätzlich implementierten Formeln:
IFERROR
…die unterstützte Tastatur-Shortcuts, welche hier zu finden sind: https://docs.telerik.com/kendo-ui/controls/data-management/spreadsheet/end-user/list-of-shortcuts
Es scheint Excel Formeln zu geben, die nicht dokumentiert sind oder per Alias verwendet werden - z.B. Runden() = Round() ist verwendbar aber nicht dokumentiert.
7. CSV-Datei-Import
Der CSV-Datei-Import-Step ist ein Step, um CSV-Dateien aus einem lokalen Verzeichnis oder vom Azure Storage in die OCT-Datenbank zu importieren. Dies dient beispielsweise dazu, wenn Exporte aus Vorsystemen in OCT verarbeitet werden sollen.
Dafür müssen passende Zieltabellen (pro CSV Dateiname) in der OCT Datenbank vorhanden sein. Diese müssen folgende Voraussetzungen erfüllen:
sie sind benannt integration.t[CSVFilename].
sie besitzen optional eine erste Spalte “RowKey”, welche nicht in den CSV Dateien als Spaltenname vorkommt.
sie besitzen optional eine zweite (erste falls RowKey nicht vorhanden) Spalte für den Tabellensuffix.
sie besitzen optional eine dritte (zweite falls kein RowKey, erste falls kein Suffix) für eine statische Spalte.
sie besitzen alle Spalten der CSV Datei mit passendem Datentyp.
Lokales Dateisystem
Diese Einstellung funktioniert nur bei einer Installation on Premise. Wenn als Quelle ein lokales Verzeichnis ausgewählt werden soll, muss die Option “Lokales Dateisystem” ausgewählt und der Pfad in das Eingabefeld “Ordnerpfad” eingetragen werden.
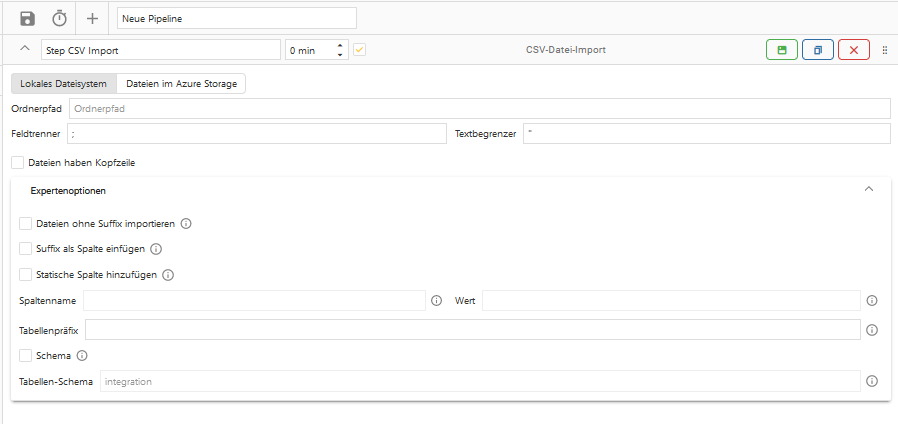
Zu beachten ist dabei:
Der Pfad muss existieren.
Alle Dateien aus dem Pfad werden importiert, wenn nur ein Teil importiert werden soll, muss ein Unterordner ausgewählt werden.
Der Nutzer “OCTService” muss Leserechte auf dem Ordner und den enthaltenen Dateien haben.
Dateien im Azure Storage
Um Dateien aus dem Azure Storage zu importieren, muss die Option “Dateien im Azure Storage” ausgewählt werden. Anschließend hat der Nutzer die Wahl zwischen dem Azure Blob Storage und dem Azure File Storage.
Wenn der Azure Blob Storage ausgewählt wurde, gibt es außerdem die Authentifizierungsarten per Zugriffsschlüssel und per Benutzerseitig zugewiesener verwalteter Identität.
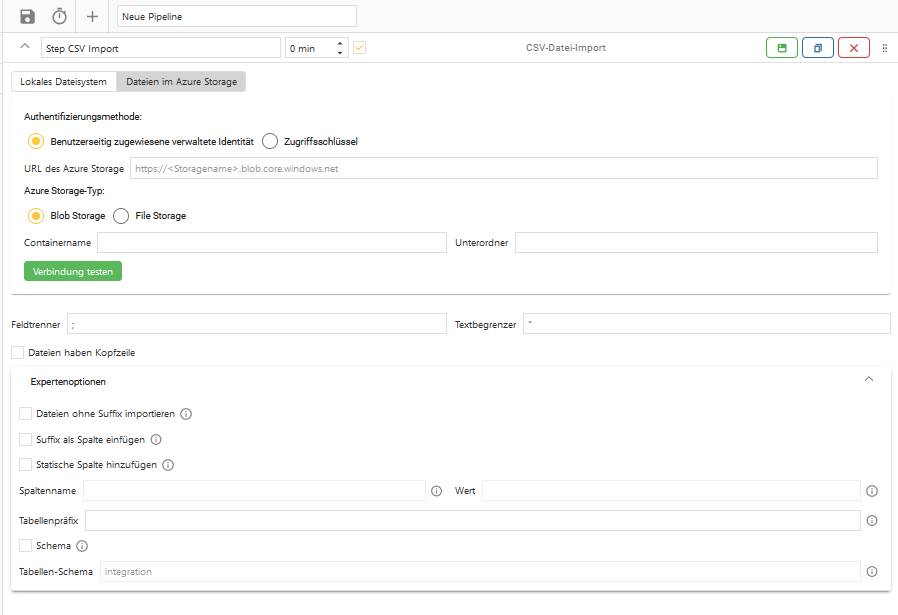
Eine Anleitung zur Verwendung des Steptyps “CSV-Datei-Import” wird im Handbuchbereich “best Practices” zur Verfügung gestellt.
8. Power-Shell-Skriptausführung
Dieser Step ruft Powershell auf und führt Befehle/ ein Skript in Powershell aus.
Er ist nur in on-premises Installationen verfügbar.
Powershell in Version 5 muss auf dem Server installiert sein.
Das Skript muss im Syntax für Powershell 5 geschrieben sein.
Powershell-Skript-Editor
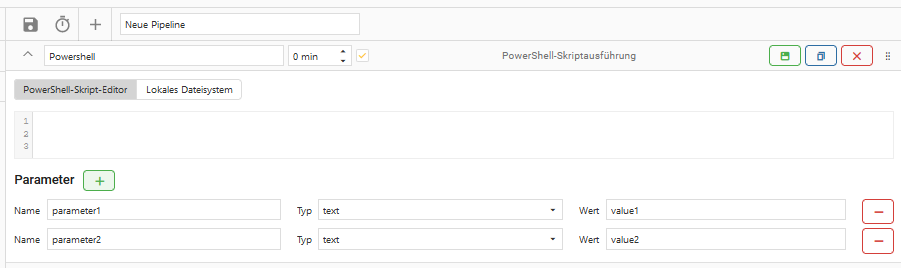
Editorfenster
Eingabefenster das PowerShell-Skript.
Parameter hinzufügen
Einer Prozedur können beliebig viele Parameter übergeben werden.
Es können globale Parameter referenziert werden mit $[Variablenname].
Ein grüner Button mit einem grünen “+” fügt einen neuen Parameter hinzu.
Name
Weißt dem Parameter einen Namen zu.
Parameter werden ohne “@” übergeben.
Typ
Definiert den Datentyp des Parameters.
Parameter können vom Typ “text” oder vom Typ “numeric” sein.
Wert
Übergibt den Parameter mit einem dazugehörigem Wert.
Mögliche Werte hängen von der Art des ausgewählten Typs ab.
Lokales Dateisystem
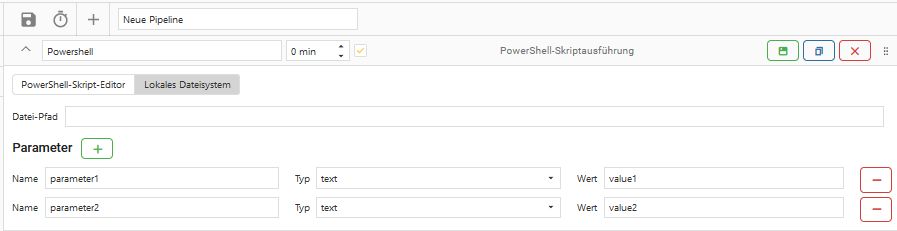
Datei-Pfad
Angabe des lokalen Verzeichnisses, in dem das PowerShell Skript liegt.
Parameter hinzufügen
Einer Prozedur können beliebig viele Parameter übergeben werden.
Es können globale Parameter referenziert werden mit $[Variablenname].
Ein grüner Button mit einem grünen “+” fügt einen neuen Parameter hinzu.
Name
Weißt dem Parameter einen Namen zu.
Parameter werden ohne “@” übergeben.
Typ
Definiert den Datentyp des Parameters.
Parameter können vom Typ “text” oder vom Typ “numeric” sein.
Wert
Übergibt den Parameter mit einem dazugehörigem Wert.
Mögliche Werte hängen von der Art des ausgewählten Typs ab.
9. XLS-Datei-Import
Der XLS-Datei-Import-Step ist ein Step, um XLS-Dateien aus einem lokalen Verzeichnis oder vom Azure Storage in die OCT-Datenbank zu importieren. Dies dient beispielsweise dazu, wenn Exporte aus Vorsystemen in OCT verarbeitet werden sollen.
Dafür müssen passende Zieltabellen (pro XLS Dateiname) in der OCT Datenbank vorhanden sein.
Lokales Dateisystem
Diese Einstellung funktioniert nur bei einer Installation on premises. Wenn als Quelle ein lokales Verzeichnis ausgewählt werden soll, muss die Option “Lokales Dateisystem” ausgewählt und der Pfad in das Eingabefeld “Ordnerpfad” eingetragen werden.
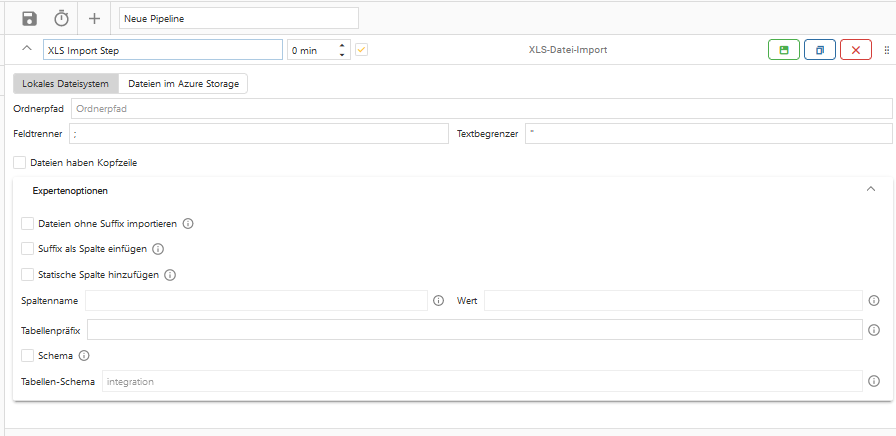
Dateien im Azure Storage
Um Dateien aus dem Azure Storage zu importieren, muss die Option “Dateien im Azure Storage” ausgewählt werden. Anschließend hat der Nutzer die Wahl zwischen dem Azure Blob Storage und dem Azure File Storage.
Wenn der Azure Blob Storage ausgewählt wurde, gibt es außerdem die Authentifizierungsarten per Zugriffsschlüssel und per Benutzerseitig zugewiesener verwalteter Identität.
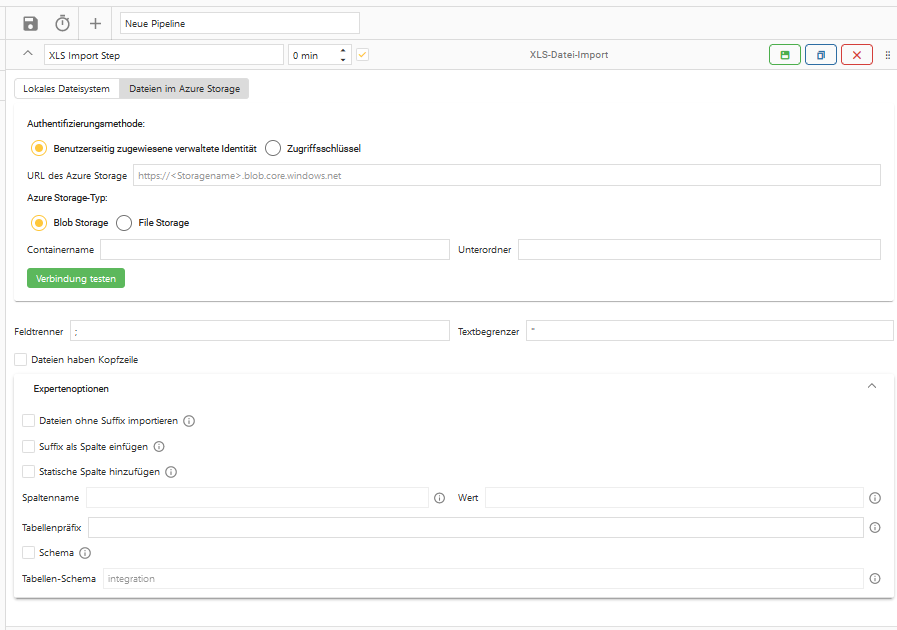
Eine Anleitung zur Verwendung des Steptyps “CSV-Datei-Import” wird im Handbuchbereich “Best Practices” zur Verfügung gestellt.